文本分析(分词)
文本分析(分词)是将非结构化文本(如电子邮件正文或产品描述)转换为针对搜索优化的结构化格式的过程。文本分析使得搜索引擎能够执行全文搜索,并返回所有相关结果,而不仅仅是精确匹配。
例如:当您搜索 Quick fox jumps,您可能想要包含 A quick brown fox jumps over the lazy dog 的文档,并且您可能还想要包含相关词(如 fast fox 或 foxes jump)的文档。
词条化处理
分析通过词条化处理使全文搜索成为可能:将文本分解成更小的块,称为词条。 在大多数情况下,这些词条是单个单词。
如果您将短语 the quick brown fox jumps 作为单个字符串编入索引,当用户搜索 quick fox 时会匹配不到。 但是,如果您对短语进行词条化并分别索引每个单词,则可以单独查找查询字符串中的每个单词。 这意味着它们可以通过 quick fox, fox brown 或其他变体来进行搜索匹配。
英语单词相对而言比较容易辨认:单词之间都是以空格或者(一些)标点隔开。 然而即使在英语词汇中也会有一些争议: you’re 是一个单词还是两个? o’clock , cooperate , half-baked ,或者 eyewitness 这些呢?
德语或者荷兰语把独立的单词合并起来创造一个长的合成词如 Weißkopfseeadler (white-headed sea eagle) , 但是为了在查询 Adler (eagle) 的时候返回查询 Weißkopfseeadler 的结果,我们需要懂得怎么将合并词拆成词组。
亚洲的语言更复杂:很多语言在单词,句子,甚至段落之间没有空格。 有些词可以用一个字来表达,但是同样的字在另一个字旁边的时候就是不同意思的长词的一部分。
显而易见的是没有能够奇迹般处理所有人类语言的万能分析器,Lucene 本身为很多语言提供了专用的分析器, 其他特殊语言的分析器以插件的形式提供。
规范化处理
把文本切割成词条(token)只是这项工作的一半。为了让这些词条(token)更容易搜索, 这些词条(token)需要被规范化处理(normalization)--这个过程会去除同一个词条(token)的无意义差别,例如大写和小写的差别。可能我们还需要去掉有意义的差别, 让 esta、ésta 和 está 都能用同一个词条(token)来搜索。你会用 déjà vu 来搜索,还是 deja vu?
更多关于文本分析的介绍可以阅读 ElasticSearch 官网文档
ideaseg 中文分词插件
Indexea 为您提供了使用 NLP 技术开发的中文分词插件 ideaseg 。
ideaseg 是一个基于最新的 HanLP 自然语言处理工具包实现的中文分词器, 包含了最新的模型数据,同时移除了 HanLP 所包含的非商业友好�许可的 NeuralNetworkParser 相关代码和数据。
HanLP 相比其他诸如 IK、jcseg 等分词器而言,在分词的准确率上有巨大的提升,但速度上有所牺牲。 通过对 HanLP 进行优化配置,ideaseg 在准确度和分词速度上取得了最佳的平衡。
与其他基于 HanLP 的插件相比,ideaseg 同步了最新 HanLP 的代码和数据,去除了无法商用的相关内容;实现了自动配置; 包含了模型数据,无需自行下载,使用简单方便。
ideaseg 提供三个模块包括:
- core ~ 核心分词器模块
- elasticsearch ~ ElasticSearch 的 ideaseg 分词插件 (最高支持 7.10.2 版本)
- opensearch ~ OpenSearch 的 ideaseg 分词插件 (默认版本 2.4.1)
ideaseg 中文分词插件已开源,地址: https://gitee.com/indexea/ideaseg
关于 ElasticSearch 的版本说明,由于从 7.11.1 版本开始 Elastic 修改 ES 的许可证,同时修改了插件的权限策略, 不再允许插件对文件进行读写。由于 HanLP 本身的模型数据很大,为了提升速度其处理机制需要在插件的数据目录下生成一些相当于缓存的文件。 因此,如��果你使用的是 ElasticSearch 请尽量用 7.10.2 或者以下的版本,推荐使用 OpenSearch 。
然而并不是所有语言都有专用分析器,而且有时候你甚至无法确定处理的是什么语言。这种情况,我们需要一些忽略语言也能合理工作的标准工具包。
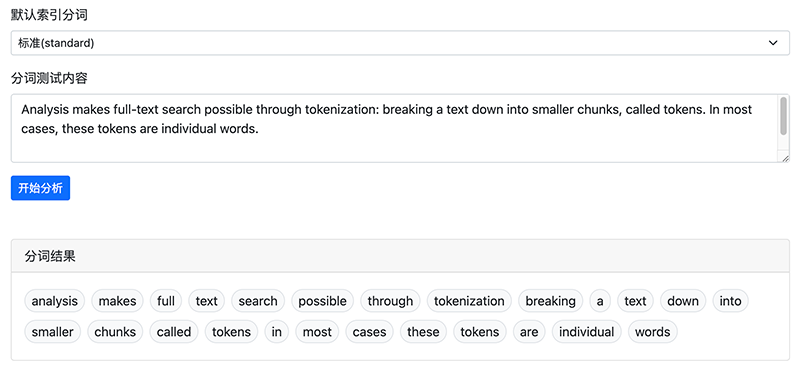
文本分词测试工具
同时 Indexea 也为您提供了一个在线的文本分析(分词)测试工具,你可以在索引的设置菜单中找到该工具:
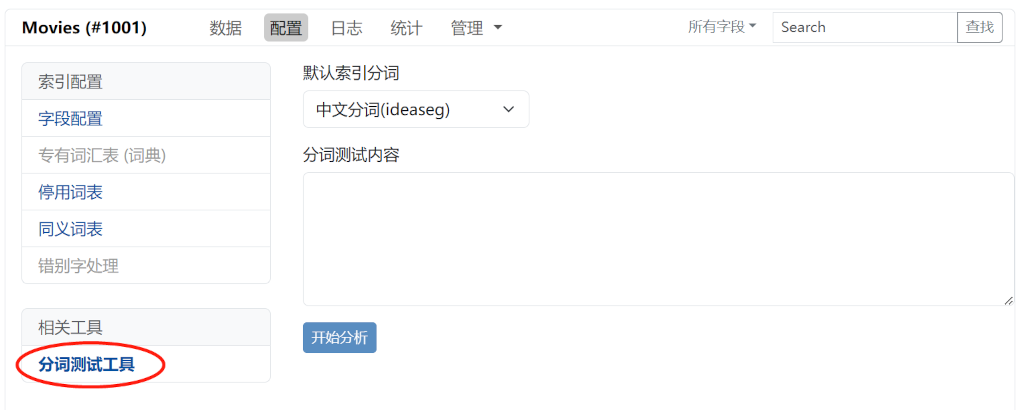
输入要分析的文本,选择合适的分词器,然后点击 开始分析 按钮。