使用 ElasticSearch 和 Transformers 实现语义搜索
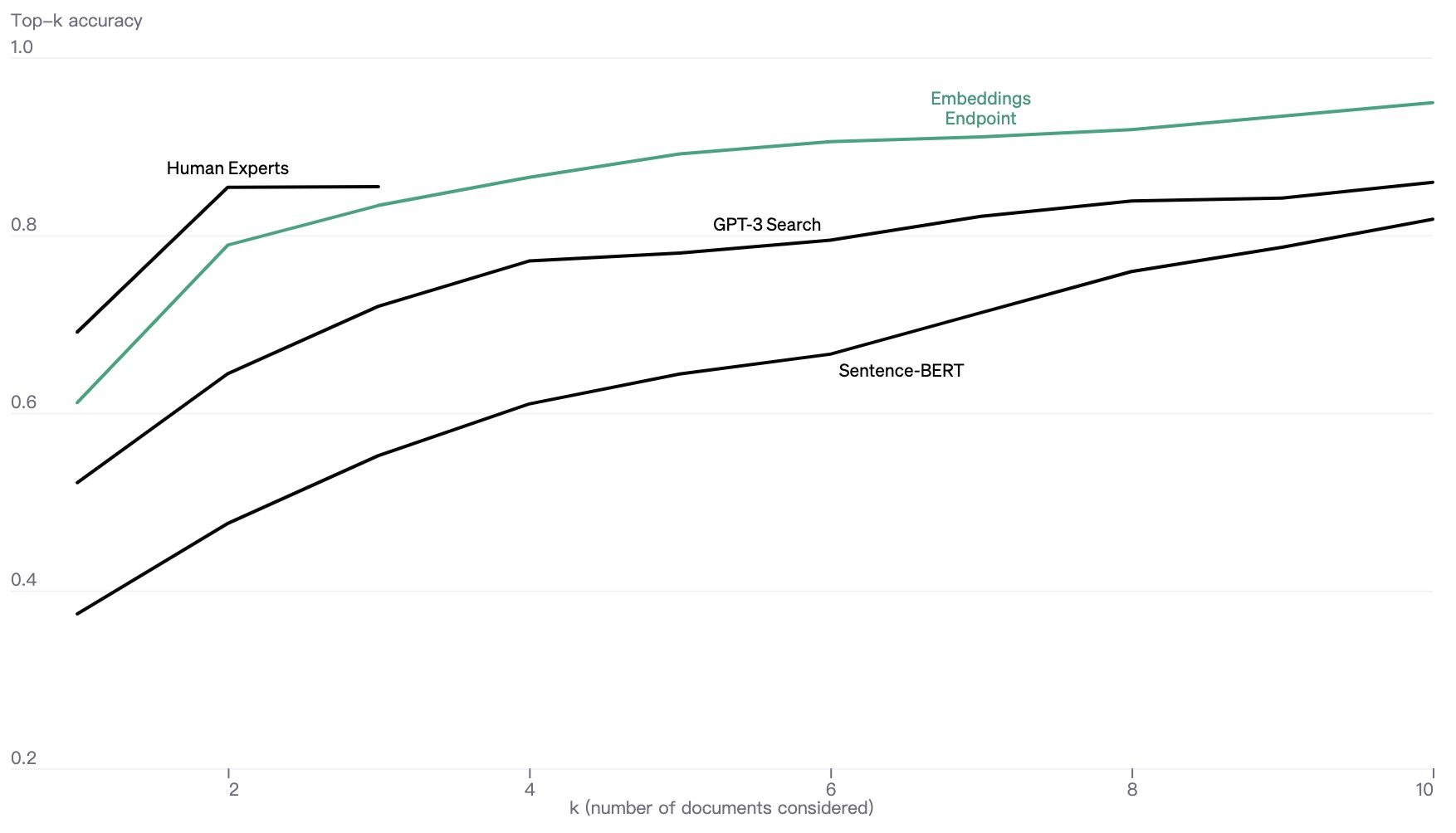
语义/矢量搜索是一种强大的技术,可以大大提高搜索结果的准确性和相关性。与传统的基于关键字的搜索方法不同,语义搜索使用单词的含义和上下文来理解查询背后的意图并提供更准确的结果。实现语义搜索的最流行的工具之一是 Elasticsearch,这是一个高度可扩展且功能强大的搜索引擎,可用于索引和搜索大量数据。在本文中,我们将探讨语义搜索的基础知识以及如何使用 Elasticsearch 实现它。在本文结束时,您将对语义搜索的工作原理以及在项目中实现语义搜索的实用技能有深入的了解。
Elasticsearch
Elasticsearch 是一个基于 Lucene 库的强大且可扩展的开源搜索引擎。它旨在处理大量非结构化数据并提供快速准确的搜索结果。Elasticsearch 使用分布式架构,这意味着它可以在多个服务器上水平扩展,以处理大量数据和流量。
Elasticsearch 建立在 RESTful API 之上,这使得它很容易与各种编程语言和工具集成。它支持复杂的搜索查询,包括全文搜索、分面搜索和地理搜索。Elasticsearch 还提供了一个强大的聚合框架,允许您对搜索结果执行复杂的数据分析。
Transformers
Transformers 是一种机器学习模型,它彻底改变了自然语言处理 (NLP) 任务,例如语言翻译、文本摘要和情绪分析。Transformers 最初是由 Vaswani 等人在 2017 年的一篇论文“注意力是你所需要的一切”中引入的,此后成为许多 NLP 任务的最新模型。
与依赖于递归神经网络(RNN)和卷积神经网络(CNN)的传统 NLP 模型不同,Transformers 使用自我注意机制来捕获句子中单词之间的关系。自我注意允许模型专注于输入序列的不同部分,以确定单词之间最重要的关系。这使得转换器在处理单词之间的长期依赖关系和上下文关系方面比传统模型更有效。
在本文中,我将使用 TensorFlow 的通用句子编码器来编码/矢量化数据。您也可以选择任何其他形式的编码器。
先决条件
在开始之前,需要如下准备工作:
- 了解 python,包括使用外部库和 IDE 的知识。
- 了解 Transformers / Vectorizers 及其输出的维度数组。
- Elasticsearch 8.6 及更高版本。
开始构建
为了构建语义搜索功能,我们使用 Python 作为后端,Elasticsearch 8.6.1 ,以及 TensorFlow 的 Universal Sentence Encoder 用于获取嵌入/向量。
先安装依赖项:
pip install elasticsearch==8.6.1
pip install tensorflow==2.10.0
安装依赖项后,首先需要文本数据。获取文本数据后,在首选 IDE 中使用 python 读取它。
from elasticsearch import Elasticsearch
import pandas as pd
import numpy as np
df = pd.read_csv('your_text_dataset.csv')
现在读取文本数据后,第一个任务是将其转换为向量或嵌入。正如我之前提到的,我使用的是 TensorFlow 的通用句子编码器,它在提供字符串时输出“512”维度的向量/嵌入。
对于其他转换器/矢量器,这将有所不同,您需要记住这一点以进一步的步骤。
让我们首先加载通用句子编码器模型,这里我已将其存储在系统中。您也可以在其 网站 上找到相关 API。
model = hub.load("path/model v4")
成功加载模型后,现在我们的下一个任务是将数据集中的文本转换为向量/嵌入,并将其存储在名为 Embeddings 的新字段/列中。
with tf.compat.v1.Session() as session:
session.run([tf.compat.v1.global_variables_initializer(), tf.compat.v1.tables_initializer()])
query_array = session.run(model(df["Text"]))
vectors = []
for i in query_array:
vectors.append(i)
df["Embeddings"] = vectors
df.to_csv("your_text_dataset_with_embeddings.csv", index=False)
注意:在这个的数据集中,有一个名为 Text 的字段/列。请根据您的数据集的情况来修改该字段名。
一旦嵌入完成并存储在新字段中,就可以将这些数据插入到前面我们安装的 Elasticsearch 中。
要插入数据,我们首先必须连接到 Elasticsearch,我们使用 python 来实现这个操作:
http_auth = ("elastic_username", "elastic_password")
es_host = "https://localhost:9200"
context = create_default_context(cafile="http_ca.crt")
es = Elasticsearch(
es_host,
basic_auth=http_auth,
ssl_context=context
)
要验证是否已建立连接,您可以先在浏览器上打开 https://localhost:9200 检查是否可以正常访问。您还可以通过运行 es.ping() 来检查来自 IDE 的连接。如果成功连接,输出应为 True。
现在我们已经建立了与 Elasticsearch 的连接,接下来继续配置 Elasticsearch 索引:
configurations = {
"settings": {
"analysis": {
"filter": {
"ngram_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15,
},
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_keywords": {
"type": "keyword_marker",
"keywords": ["example"]
},
"english_stemmer": {
"type": "stemmer",
"language": "english"
},
"english_possessive_stemmer": {
"type": "stemmer",
"language": "possessive_english"
}
},
"analyzer": {
"en_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase",
"ngram_filter",
"english_stemmer",
"english_possessive_stemmer",
"english_stop"
"english_keywords",
]
}
}
}
},
"mappings": {
"properties": {
"Embeddings": {
"type": "dense_vector",
"dims": 512,
"index": True,
"similarity": "cosine"
},
}
}
}
configurations["settings"]
上述配置可以让我们在插入数据时进行索引配置,让我们仔细看看一些重要的参数。
- “type”:类型必须始终设置为“dense_vector”。这样做是为了让 ElasticSearch 了解这些是向量,并且不会自行为此字段分配浮点类型。
- “dims”:也就是维度。就像我之前提到的,通用句子编码器产生并输出“512”维度,这就是为什么我们在参数中提供“512”的原因。
- “index”:索引必须设置为“True”,以便创建此字段并在 ElasticSearch 中具有 dense_vector 类型的特性。
- “similarity”:求余弦相似性。
配置索引后,继续创建索引:
es.indices.create(index='my_new_index',
settings=configurations["settings"],
mappings=configurations["mappings"]
)
这里我们将索引命名为 “my_new_index”,最后我们准备将数据插入到 Elasticsearch 上的这个索引中:
actions = []
index_name = 'my_new_index'
for index, row in df.iterrows():
action = {"index": {"_index": index_name, "_id": index}}
doc = {
"id": index,
"Text": row["Text"],
"Price": row["Price"],
"Quantity": row["Quantity"],
"Embeddings": row["Embeddings"]
}
actions.append(action)
actions.append(doc)
es.bulk(index=index_name, operations=actions)
搜索
一旦完成数据插入后,就可以搜索这些数据并提出一些相关问题。我们从一个我们想要获得答案的问题开始。
query = "Which is the latest phone available in your shop?"
由于我们要在 Elasticsearch 上进行语义搜索,因此需要将�此文本转换为嵌入/向量。
with tf.compat.v1.Session() as session:
session.run([tf.compat.v1.global_variables_initializer(), tf.compat.v1.tables_initializer()])
query_array = session.run(model([query])).tolist()[0]
将文本转换为嵌入/向量后,就根据 Elasticsearch 中的现有数据搜索此文本。为此,我们首先必须构建一个查询从 Elasticsearch 获取数据。
query_for_search = {
"knn": {
"field": "Embeddings",
"query_vector": query_array,
"k": 5,
"num_candidates": 2414
},
"_source": [ "Text"]
}
我们通过上述代码在 Elasticsearch 进行查询。在我们查看下一步之前,先看看这个查询:
- "knn": Elasticsearch 支持 K-Nearest Neighbors 又名 kNN 算法,并且已经在 Elasticsearch 中可用。您不需要单独训练它。
- "field": 嵌入/向量存储在 Elasticsearch 中的字段名。
- "query_vector": 输入的
向量/嵌入形式 "k": 需要获取的结果数 - "num_candidates": 以令牌为单位的输出/搜索结果的长度。
- "_source": 必须从中提供输出/搜索结果的字段名。
开始搜索:
result = es.search(
index="my_new_index",
body=query_for_search)
result0["hits"]
借助上述查询,您将能够从之前存储数据的索引中获取搜索结果。
请记住,您只能对具有配置字段的索引执行语义搜索,包含嵌入/向量的字段类型必须为“dense_vector”,并且查询/问题和存储在 Elasticsearch 中的数据的向量维度必须完全相同。例如,在上面的教程中,我们在 Elasticsearch 中的数据处于“512”维度中,并且在我们继续搜索操作之前,查询/问题也转换为“512”维度。
结论
语义搜索是一种强大的工具,可以通过理解单词的含义和上下文来大大提高搜索结果的准确性和相关性。Elasticsearch 是一个高度可扩展且灵活的搜索引擎,可用于实现从电子商务到医疗保健的各种应用程序的语义搜索。通过利用 Elasticsearch 强大的搜索和索引功能,以及查询扩展、同义词检测和实体识别等技术,您可以构建一个语义搜索系统,提供快速准确的结果。无论您是开发人员、数据科学家还是企业主,使用 Elasticsearch 掌握语义搜索都可以帮助您从数据中发掘新的见解和机会。
本文的完整代码请看 https://github.com/Pritam868/Semantic-Search-ElasticSearch
本文译自 https://medium.com/@pablopaul1999/semantic-search-using-transformers-and-elasticsearch-6e968fdd85d5