OpenSearch 2.9.0 新特性介绍
OpenSearch 2.9.0 已经发布,带来了一些新功能,旨在帮助您构建更好的搜索解决方案,并将更多机器学习(ML)整合到您的应用程序中,同时还更新了用于安全分析工作负载、地理空间可视化等方面的功能。此版本还提供了新的压缩编解码器,可以显著提高性能并减小索引大小。对于开发人员而言,实验性扩展软件开发工具包(SDK)简化了在 OpenSearch 之上构建功能和功能的工作。以下是 OpenSearch 和 OpenSearch Dashboards 最新版本的一些亮点;若想了解更详细的内容,请查阅发布说明。
通过搜索管道提升搜索功能
搜索专业人员希望引入新的方式来增强搜索查询和结果。通过搜索管道的普遍可用性,您可以配置一个或多个处理器的列表,以在 OpenSearch 内部转换搜索请求和响应。通过在 OpenSearch 中集成处理器,如查询重写器或结果重新排序器,您可以使搜索应用程序更准确高效,并减少对定制开发的需求。
搜索管道包含三个内置处理器,filter_query、rename_field 和 script request,以及新的面向开发人员的 API,可使希望构建自己处理器的开发人员能够这样做。您可以在 OpenSearch Playground 中自行探索搜索管道。这些功能是项目学习和开发的持续优先事项;如果您想对新的处理器或其他想法提供意见,请查阅意见征询。
更轻松地构建语义搜索应用程序
OpenSearch 项目在 OpenSearch 2.4.0 中发布了实验性的神经搜索功能。随着 2.9.0 版本的发布,神经搜索已经可以在您的搜索工作负载中进行生产使用。这些工具允许您将文档和查询向量化,并使用 k 最近邻(k-NN) 搜索这些转换后的向量,因此您可以利用 OpenSearch 的向量数据库功能来支持语义搜索等应用程序。现在,您可以将传统的 BM25 词汇搜索与深度学习支持的语义搜索相结合,以及为提高搜索相关性调整查询的新方法。
集成和管理您的 ML 模型在 OpenSearch 集群中
像语义搜索这样的应用程序需要集成 ML 模型。此版本通过 ML 框架的正式推出,使操作化和集成 ML 模型变得更加简单。ML 框架最初作为 2.4.0 版本的实验性功能推出,它允许您将自己的 ML 模型上传到 OpenSearch,支持从多种工具(如 PyTorch 和 ONNX)加载文本嵌入模型,并准备将模型用于神经搜索和其他应用程序的部署。在为正式推出做准备的过程中,OpenSearch 2.9.0 还引入了 ML 模型访问控制功能,允许管理员管理通过该框架集成的单个模型的访问权限。
集成外部管理的 ML 模型
OpenSearch 2.9.0 通过启用集成器,使集成者能够轻松地创建连接到人工智能(AI)服务和 ML 平台的连接器,只需在 JSON 中定义蓝图即可。这些 AI 连接器使用户能够使用托管在连接的服务和平台上的模型来支持语义搜索等 ML 工作负载。构建连接器的说明已包含在文档中。例如,此版本包含了适用于 Amazon SageMaker 托管模型的连接器。该项目将在不久的将来发布 Cohere Rerank 和 OpenAI ChatGPT 的连接器,并将添加其他集成。
使用向量数据库增强搜索功能
随着此版本的发布,OpenSearch 的近似 k-NN 实现支持使用 Facebook AI Similarity Search(FAISS)引擎进行查询的预过滤。现在,您可以在使用 FAISS 构建的 k-NN 索引上,在执行最近邻搜索之前使用元数据来过滤查询,从而提供更高效的 k-NN 搜索和更好的性能。之前,OpenSearch 仅支持 Lucene 索引的预过滤。
OpenSearch k-NN 的另一个更新是支持 Lucene 的字节大小向量。用户现在可以选择摄取和使用每个维度压缩为一个字节大小的向量。这样可以减小加载、保存和执行向量搜索所需的存储和内存要求,但可能会导致精度下降。
在 OpenSearch Dashboards 中构建监视器和探测器
现在,您可以直接将警报和异常与您用于监视环境的主要仪表板叠加在一起。通过将 OpenSearch 的警报和异常检测工具与 OpenSearch 可视化工具集成,此版本简化了监视系统和基础架构的用户工作。用户还可以直接从 OpenSearch Dashboards VISLIB 图表或线性可视化创建警报监视器或异常探测器,然后查看叠加在配置的可视化上的警报或异常��。已经定义了监视器或探测器的用户现在可以将其与可视化关联起来。这样就不再需要在可视化工具和创建警报或异常探测器所需的信息之间切换,更便于探索数据并发现发现。
使用复合监视器获取更有意义的警报通知
2.9.0 版本中新增的复合监视器是 OpenSearch 警报工具箱的又一个补充。 复合监视器允许用户将由多个单独监视器生成的警报链接成单一的工作流程。只有当所有监视器之间的组合触发条件都满足时,用户才会收到通知。这使得用户可以基于多个标准分析数据源,并更细致地了解数据。现在,用户有机会创建针对特定通知对象的目标通知,同时减少警报的总量。
通过新的索引压缩选项提高性能
OpenSearch 提供内置编解码器,对索引进行压缩,影响索引文件的大小和索引操作的性能。之前的版本包括两种编解码器类型:默认索引编解码器优先考虑性能,而 best_compression 编解码器在索引时实现高压缩和较小的索引大小,但可能导致索引时 CPU 使用率增加,并且可能导致较高的延迟。随着 2.9.0 版本的发布,OpenSearch 新增了两个新的编解码器,即 zstd 和 zstd_no_dict,它们使用了 Facebook 的 Zstandard 压缩算法。这两个编解码器旨在在压缩和性能之间取得平衡,其中 zstd_no_dict 不包含字典压缩功能,因此在索引和搜索性能上可能会略微增加索引大小。
这两个新的编解码器 zstd 和 zstd_no_dict 提供了一种配置压缩级别作为索引设置(index.codec.compression_level)的选项,其他编解码器不支持这一设置。压缩级别在压缩比和速度之间进行权衡;较高的压缩级别会导致较小的存储空间,但在压缩时会消耗更多的 CPU 资源。优化这些权衡取决于工作负载的多个方面,为了获得整体性能的最佳优化,最好尝试多种级别。
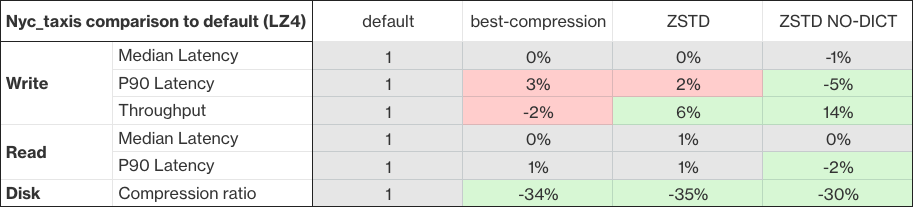
通过上面的表格可以看出,使用 NYC 出租车数据集进行的测试显示,与默认编解码器相比,使用 zstd 可以实现高达 35%的压缩改进,并且 zstd 的吞吐量增加了 7%,而 zstd_no_dict 的吞吐量增加了 14%。在升级到 2.9.0 版本后,用户可以通过修改新建或现有索引的设置来实现性能改进。
使用安全分析简化威胁检测
安全分析现在支持遵循开放网络安全模式架构 OCSF 的日志数据新摄取模式,可以支持 Amazon Route 53、AWS CloudTrail 和 Amazon Virtual Private Cloud(Amazon VPC)的 OCSF 日志。OpenSearch 安全分析的关联引擎也已经正式推出。您可以创建自定义关联规则,显示跨不同日志源(如 DNS、Netflow 和 Active Directory)的可视化知识图和发现列表。这些知识图可用于安全调查,以分析相关发现,帮助您识别组织中不同系统之间的威胁模式和关系。使用这些知识图可以帮助您更快地应对潜在的安全威胁。
对地理空间形状数据进行聚合指标
OpenSearch 使用 geoshape 和 geopoint 字段类型存储地理空间数据。在之前的版本中,用户能够对 geopoint 数据类型执行聚合;而在 2.9.0 版本中,OpenSearch 还通过 API 支持对 geoshape 数据类型进行聚合作为后端功能。此版本增加了对 geoshape 数据类型的支持,包括三种类型的聚合:geo_bounds,一种度量聚合,计算包含字段中所有地理值的边界框;geo_hash,一种多桶聚合,将地理形状分组到表示网格中的桶中;geo_tile,一种多桶聚合,将地理形状分组到表示地图瓦片的桶中。
监控您的分片和索引的健康状态
OpenSearch 提供了一系列指标,帮助您监控 OpenSearch 集群的健康状态。此版本增加了 CAT shards 和 CAT indices 监视器。这些更新允许您监控所有主分片和副本分片的状态,以及与索引健康和资源使用相关的信息,以支持运行时间。
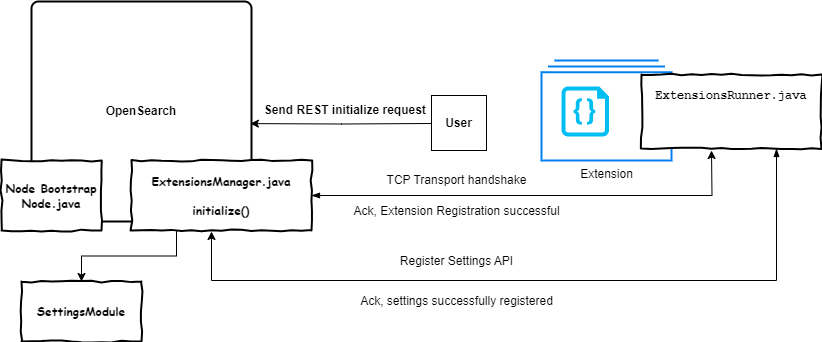
使用新的 SDK 扩展 OpenSearch 的功能
OpenSearch 项目维护了一组插件库,可以在不同的工作负载和用例中扩展 OpenSearch 的功能。由于某些原因,插件在 OpenSearch 进程内运行,这意味着它们必须保持版本兼容,并且它们的资源会随着 OpenSearch 集群的规模而扩展。对于开发人员来说,构建新的插件需要相当熟悉 OpenSearch 的架构和代码库。
一些开发人员希望有一种构建与 OpenSearch 兼容工具的方法,可以缓解这些限制。为了解决这个问题,此版本引入了一个实验性的 SDK,为开发人员提供了构建 OpenSearch 扩展的工具。OpenSearch Extensions SDK 提供了与 OpenSearch 和其他已安装的插件和扩展进行通信的规范化接口,允许扩展与 OpenSearch 版本解耦,解耦资源,并引入许多其他设计变更,旨在使开发人员更容易构建和用户部署在 OpenSearch 上的新创新。如要访问 SDK,请查看 opensearch-sdk-java 存储库。
开始使用
您可以在此处下载最新版本的 OpenSearch,并在 Playground 中探索 OpenSearch Dashboards。有关此版本的更多信息,请参阅发布说明和文档发布说明。你也可以在社区论坛上发表您对此版本的反馈!
(注意:以上内容是对原文的翻译,可能会有细微的语义调整,但力求保持原意和信息准确性。如果您对某些特定术语或内容有疑问,欢迎进一步探讨。)