常用的查询条件
查询条件类似数据库应用中的 WHERE 子句,用来确定搜索的约束条件。例如搜索今年内的文章,搜索某个品牌的产品等等。
Indexea 提供的查询条件包括如下几类:
一. 全文匹配
全文匹配查询是作为搜索引擎最核心的能力,也是区别于一般数据库检索的最基本的查询条件。
match
而全文匹配查询 match 是最重要查询。无论需要查询什么字段,match 都应该是首选的查询方式。它是一个高级全文查询 ,既能处理全文字段,又能处理精确字段匹配。match 查询主要的应用场景就是进行全文搜索。
下面我们用一个简单例子来说明全文搜索是如何工作的:
{
"query": {
"match": {
"title": "QUICK!"
}
}
}
这个查询最终执行下来的步骤是:
-
检查字段类型
标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析。
-
分析查询字符串
将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。
-
查找匹配文档
用 term 在倒排索引中查找 quick 然后获取一组包含该项的文档。
-
为每个文档评分
用 term 查询计算每个文档相关度评分 _score ,这是种将 TF 词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和 IDF 反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。
上述查询我们得到如下结果:
"hits": [
{
"_id": "1",
"_score": 0.5,
"_source": {
"title": "The quick brown fox"
}
},
{
"_id": "3",
"_score": 0.44194174,
"_source": {
"title": "The quick brown fox jumps over the quick dog"
}
},
{
"_id": "2",
"_score": 0.3125,
"_source": {
"title": "The quick brown fox jumps over the lazy dog"
}
}
]
结果说明:
- 文档 1 最相关,因为它的 title 字段更短,即 quick 占据内容的一大部分。
- 文档 3 比 文档 2 更具相关性,因为在文档 3 中 quick 出现了两次。
match_phrase 短语匹配
就像 match 查询对于标准全文检索是一种最常用的查询一样,当你想找到彼此邻近搜索词的查询方法时,就会想到 match_phrase 查询。
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含 全部 搜索词项,且 位置 与搜索词项相同的文档。 比如对于 quick fox 的短语搜索可能不会匹配到任何文档,因为没有文档包含的 quick 词之后紧跟着 fox 。
一个被认定为和短语 quick brown fox 匹配的文档,必须满足以下这些要求:
- quick 、 brown 和 fox 需要全部出现在域中
- brown 的位置应该比 quick 的位置大 1
- fox 的位置应该比 quick 的位置大 2
如果以上任何一个选项不成立,则该文档不能认定为匹配。
二. bool 组合匹配
组合查询 bool 是使用 AND、OR、NOT 等逻辑对其他查询进行组合的查询,包括四种逻辑分别是:must, should, must_not。
一个最基本的例子是:
{
"query": {
"bool": {
"must": { "match": { "title": "quick" } },
"must_not": { "match": { "title": "lazy" } },
"should": [
{ "match": { "title": "brown" } },
{ "match": { "title": "dog" } }
]
}
}
}
这个查询类似于 SQL 语句,当又不那么确切,因为 should 并非必要条件:
SELECT * FROM xxxxx
WHERE title LIKE '%quick%'
AND title NOT LIKE '%lazy%'
AND (title LIKE '%brown%' OR title LIKE '%dog%')
以上的查询结果返回 title 字段包含词项 quick 但不包含 lazy 的任意文档。目前为止,这与 bool 过滤器的工作方式非常相似。
区别就在于两个 should 语句,也就是说:文档可以但不是必须要包含 brown 或 dog 这两个词项,但如果一旦包含,我们就认为它们更相关。
得到的结果是:
{
"hits": [
{
"_id": "3",
"_score": 0.70134366,
"_source": {
"title": "The quick brown fox jumps over the quick dog"
}
},
{
"_id": "1",
"_score": 0.3312608,
"_source": {
"title": "The quick brown fox"
}
}
]
}
文档 3 比文档 1 的评分更高是因为它同时包含 brown 和 dog 。
- must
必要条件:子句(查询)必须出现在匹配的文档中,该条件会有助于 _score 评分。
- must_not
排除条件:子句(查询)不得出现在匹配的文档中。该语句不会影响评分,它的作用只是将不相关的文档排除
- should
充分条件:子句(查询)应出现在匹配的文档中,但并非必要条件。
组合查询可以使用上述几种逻辑对其他几种查询条件进行组合,同时组合查询也可以嵌套组合查询。
三. 精确匹配
精确匹配是通过结构化查询(Structured search) 探询那些具有内在结构数据的过程。比如日期、时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作。比较常见的操作包括比较数字或时间的范围,或判定两个值的大小。
文本也可以是结构化的。如彩色笔可以有离散的颜色集合: 红(red) 、 绿(green) 、 蓝(blue) 。一个博客可能被标记了关键词 分布式(distributed) 和 搜索(search) 。电商网站上的商品都有 UPCs(通用产品码 Universal Product Codes)或其他的唯一标识,它们都需要遵从严格规定的、结构化的格式。
在结构化查询中,我们得到的结果总是非是即否,要么存于集合之中,要么存在集合之外。结构化查询不关心文件的相关度或评分;它简单的对文档包括或排除处理。
这在逻辑上是能说通的,因为一个数字不能比其他数字 更 适合存于某个相同范围。结果只能是:存于范围之中,抑或反之。同样,对于结构化文本来说,一个值要么相等,要么不等。没有 更似 这种概念。
当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存,所以请尽可能多的使用过滤式查询。
term 字段匹配
term 用来查找精确的值。如查找价格为 20 的商品:
{
"term": {
"price": 20
}
}
也可以对字符串进行查找:
{
"term": {
"companyName": "Indexea"
}
}
同时你也可以指定多个值来进行匹配,例如下列查询返回字段值为 gitee 或者 indexea 中的任一个:
"terms": {
"site": [ "gitee", "indexea" ]
}
terms 多值匹配
terms_set 多值匹配
terms_set 比起前面的 terms 多了一个条件就是指定最小匹配数。如果你指定了最小匹配数为 2,那么只有当匹配到 2 个值时,才会返回结果。
使用场景:例如我们希望查找同时具备多种编程技能的求职者,我们可以使用 terms_set :
{
"terms_set": {
"skills": ["java", "javascript"]
}
}
查询条件添加界面如下图所示:
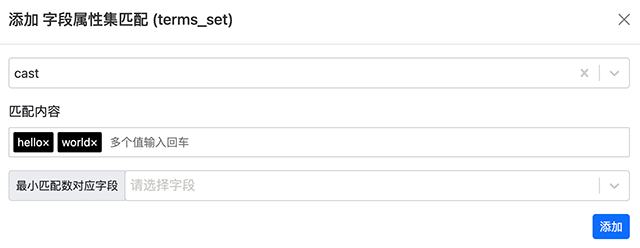
你可以通过选择一个字段,并使用该字段值作为最小需要匹配到的数量。
四. 部分匹配
你可能已经注意到,目前为止前面所介绍的查询都是针对整个词的操作。为了能匹配,只能查找倒排索引中存在的词,最小的单元为单个词。
但如果想匹配部分而不是全部的词该怎么办? 部分匹配 允许用户指定查找词的一部分并找出所有包含这部分片段的词。
与想象的不太一样,对词进行部分匹配的需求在全文搜索引擎领域并不常见,但是如果读者有 SQL 方面的背景,可能会在某个时候实现一个 低效的全文搜索 用下面的 SQL 语句对全文进行搜索:
WHERE text LIKE "%quick%"
AND text LIKE "%brown%"
AND text LIKE "%fox%"
prefix 前缀匹配
prefix 查询是一个词级别的底层的查询,它不会在搜索之前分析查询字符串,它假定传入前缀就正是要查找的前缀。
默认状态下, prefix 查询不做相关度评分计算,它只是将所有匹配的文档返回,并为每条结果赋予评分值 1 。它的行为更像是过滤器而不是查询。 prefix 查询和 prefix 过滤器这两者实际的区别就是过滤器是可以被缓存的,而查询不行。
wildcard 通配符匹配
与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询,与前缀查询不同的是它允许指定匹配的正则式。它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符。
下面查询会匹配包含 W1F 7HW 和 W2F 8HW 的文档:
{
"query": {
"wildcard": {
"postcode": "W?F*HW"
}
}
}
regexp 正则表达式匹配
如果想匹配只以 W 开始并跟随一个数字的所有邮编, regexp 正则式查询允许写出这样更复杂的模式:
{
"query": {
"regexp": {
"postcode": "W[0-9].+"
}
}
}
这个正则表达式要求词必须以 W 开头,紧跟 0 至 9 之间的任何一个数字,然后接一或多个其他字符。
wildcard 和 regexp 查询的工作方式与 prefix 查询完全一样,它们也需要扫描倒排索引中的词列表才能找到所有匹配的词,然后依次获取每个词相关的文档 ID ,与 prefix 查询的唯一不同是:它们能支持更为复杂的匹配模式。
这也意味着需要同样注意前缀查询存在性能问题,对有很多唯一词的字段执行这些查询可能会消耗非常多的资源,所以要避免使用左通配这样的模式匹配(如: *foo 或 .*foo 这样的正则式)。
数据在索引时的预处理有助于提高前缀匹配的效率,而通配符和正则表达式查询只能在查询时完成,尽管这些查询有其应用场景,但使用仍需谨慎。
fuzzy 模糊匹配
返回包含与搜索词相似的词的文档,这些词由 Levenshtein 编辑距离 测量。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可能包括:
- 更改字符(box → fox)
- 删除字符(b 缺少 → 缺少)
- 插入字符(原文如此 → 原文如此 k)
- 转置两个相邻字符(act → cat)
为了查找相似的词,查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。然后,查询将为每个扩展返回完全匹配项。
fuzzy 对中文基本无效果。
以上内容部分引用自 ElasticSearch 官方文档 。